Q. Character set, charset, coded character set, code page, encoding, how can I make some sense?
A. There is no “one line answer,” so please read the article :-)
Introduction
Although you can search the web and find a lot of different definitions, it is obvious from the questions or comments on newsgroups or web sites that very few people really “grok” these basic concepts.
So I will try to give here something beyond definitions (in fact, I don’t think I will give definitions at all :-))
What I want is to give you a way of looking at things, understand how they fall together and what the relation between the various concepts is.
No clue why I think that I can do it, but I will take my chance anyway :-).
Character set
It is best to think of a character set as “a bunch of characters.”
Think of it as the set of characters (the box) that a typographer used when he started to put together a book using “the old ways,” with lead type.
It has nothing to do with computers, nothing to do with the exact shape of each character.
There is no order and there are no numbers associated with the characters.
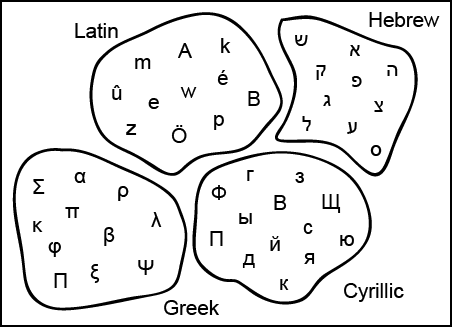
Coded character set (charset, code page)
The computer is not as smart as a typographer, and cannot handle the abstract notion of “character.” The computer can only handle numbers, and the only way to represent text in a computer was to associate a number to each character.
Since there was no one single computer manufacturer, several different mapping systems where created (they did not get together to come up with a common standard, they where competing, remember?)
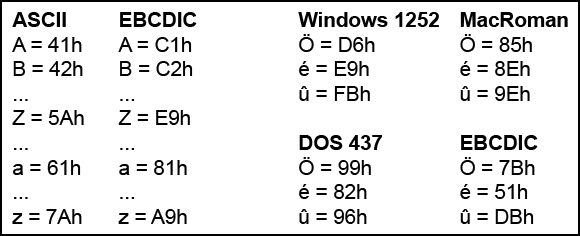
As you can imagine, this made the text transfer between various systems quite messy.
But, anyway, the “bucket of characters” plus the numeric mapping is named “coded character set” or “code page.”
The “code page” term is more popular in the Windows world, charset in the Web world, and “coded character set” is used mostly in the UNIX world.
Encoding
The two concepts explained before are still not enough for a computer. They are still at an abstract level, just characters associated with numbers.
The encoding is the mechanism that takes these abstract concepts and maps them to the actual bytes.
It is easy to confuse things because the most popular mechanism is to take the number for the character you need and store it in a byte.
But it becomes more obvious that these are different beasts once somewhere on the way you have a bottleneck. A good example is the email.
Some of the early systems where unable to handle 8 bits data, so mechanisms where created to overcome this (i.e. UUEncode, MIME, Base64, Quoted-Printable, escaping, etc.)
If I receive a message and the subject is “Resum=E9”, the encoding tells you that =E9 represents the E9h character. But you have no clue what it really is unless you know the code page.
This is why in email messages should include both pieces of information:
Content-type: text/plain; charset=ISO-8859-1 Content-transfer-encoding: Quoted-Printable
Also, for the email header, all info must to be present (RFC 2047). Here is “Resumé” represented in various combinations encoding-charset:
=?ISO-8859-1?Q?Resum=E9?=
=?ISO-8859-1?B?UmVzdW3p?=
=?UTF-8?B?UmVzdW3DqQ==?=
(=?<CharSet>?<Encoding>?<Encoded text>?=).
So, “the thing” that tells you that E9h is represented as =E9 is the encoding, and “the thing” that tells you that E9h is é is the code page.
Some consequences
Ok, let’s say you read at all of the above, and grok it.
Now you can flex the muscle of your new understanding and read some of the documents dealing with these issues. Hopefully you will be able to understand better some of them (and spot the mistakes in others).
And you can also come up with a couple of conclusions:
Unicode is a coded character set
Since “Unicode provides a unique number for every character” (http://www.unicode.org/standard/WhatIsUnicode.html) this makes is a coded character set (or charset, or code page), not a character set or encoding.
I will talk a bit about Unicode (and UTF) in the next article.
Sorting by the numeric codes is wrong
Since there are so many different code pages for the same language, it is obvious that sorting by the numeric values will give different sorting orders on different platforms. Since the sorting in English (or German, or Russian) exists independent of any computer, it means that some (or all) of the results are wrong.
So, never-ever sort by numeric value!