Story
This is a small tool that started as a private investigation into the functionality of some Windows API.
At some point somebody complained that GetGlyphIndices is not surrogate-aware and does not work for characters outside BMP (Basic Multilingual Plane).
So I have started a small application to test the claim.
And it was true!
So the next step was: “let’s find a solution!” and shortly after I had my own routine doing almost the same thing, but doing it’s own parsing of the cmap OpenType table.
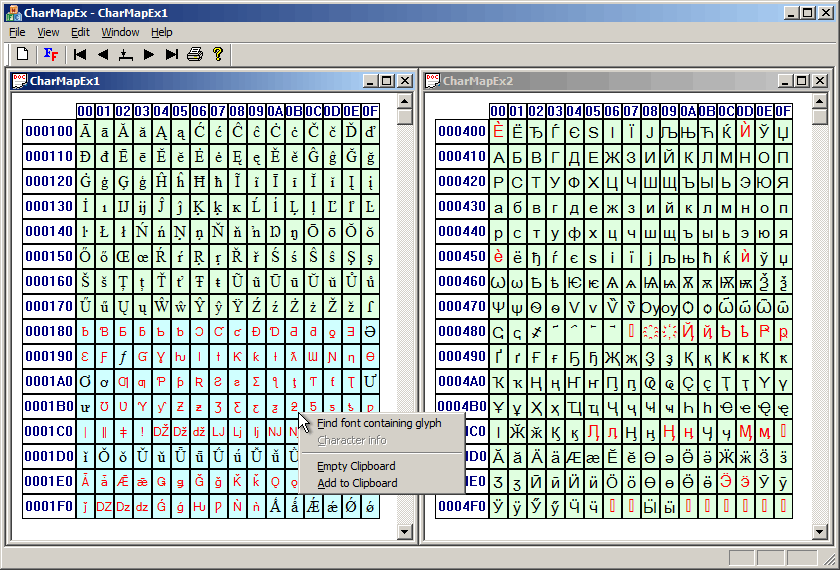
To test that I needed an easy way to change the font and to visualize the results. Then I wanted to know what font contains a certain character (make sure to right-click :-)
And little by little, it grew into something that might be useful to others. And some friends also asked: “Why don’t you give it away?”
So, here it is, for your benefit and/or enjoyment :-)
Future plans:
- Fix printing
- Determine glyph presence using Uniscribe (
ScriptGetCMap) - Tile vertical and horizontal
- Allow users to assign a font for each block
- Take block names from the Unicode file “Blocks.txt”
- Show Unicode information for each character using the Unicode files (“UnicodeData.txt,” Unihan.txt,” and maybe others)
- Maybe publish some of the code
So make sure to select “Help” -> “Check for updates…” once in a while :-)
Disclaimer
In general, I am not responsible (irresponsible?) for any problem with this tool. It is provided “as is,” take or leave it :-)
Download
Ok now, there you go: CharMapEx.zip (contains the executable)
Good luck!
[…] CharMapEx, una extraña aplicación especializada que tiene razones más geek para aparecer que BabelMap y […]
[…] CharMapEx, a weird specialized application that has geekier reasons for appearing than BabelMap and […]
[…] CharMapEx, một ứng dụng chuyên biệt kỳ lạ có những lý do khó xuất hiện hơn BabelMap […]
[…] CharMapEx, outo erikoistunut sovellus, jolla on nerokkaampia syitä esiintyä kuin BabelMap ja CatchChar. […]
[…] CharMapEx, một ứng dụng chuyên biệt kỳ lạ có những lý do khó xuất hiện hơn BabelMap […]
[…] Reply no.: 60, 10 Aug 2010, 12:33 AMMihai: Sorry Kit, I did not check this comments for a while.Yes, U+0162, U+0163 render with comma (bad), and U+021A, U+021B are missing.Tested on Froyo (2.2), with Nexus One. Used to see the font, and I have also got the font and installed on Windows, then inspected it with this http://mihai-nita.net/2007/09/08/charmapex-some-kind-of-character-map. […]
[…] CharMapEx, a weird specialized application that has geekier reasons for appearing than BabelMap and […]
I have problem that also ScriptGetCMap receiving string with 1 surrogate (= 2 characters) fills output buffer with 2 the same characters (where GetGlyphIndices gives 2x ffff) even I think I have selected font containing this surrogate
is there any example source I can compare with mine? (different charmap in CreateFontW gives just different replacement characters in ScriptGetCMap’s output)
thanks
Reading from here http://msdn.microsoft.com/en-us/library/windows/desktop/dd319122%28v=vs.85%29.aspx
That was my reason to put this together: there is not much out there to help with this.
And (of course) to play and learn.
In general one does not need to care if the glyph was in the selected font or not, very often Windows will do
it’s magic and will find some fallback / substitution.
I did not consider my code is not nice enough to share, or to use in some kind of “production”
It was mostly a way for me to learn about the cmap tables in OpenType fonts.
This is how it started in fact. The GUI came after that, a friendlier visualization to replace the initial command line toy application.
But basically what I do is parse the cmap table documented here: https://www.microsoft.com/typography/otspec/cmap.htm
(main OpenType spec here https://www.microsoft.com/typography/otspec/default.htm)
With quite a bit of help from dumping fonts in text format with tools like Adobe Font Development Kit for OpenType (AFDKO)
(http://www.adobe.com/devnet/opentype/afdko.html) and TTX (http://sourceforge.net/projects/fonttools/)
I found that dumping the text with a good tool and comparing the results with what I did seemed easier that some API that I would have to know how to use :-)
Mihai
[…] CharMapEx […]
[…] CharMapEx […]
[…] CharMapEx […]
[…] CharMapEx […]
Hi ,
I found your char map tool. I was wondering how did you find names for all characters ? Did you create list? Or are you receiving name from font file …
How do you know what character set is selected ?
Thanks for information.
Lubo
Those are really Unicode blocks, with the names in the Blocks.txt
(part of regular Unicode releases, you can find it at
ftp://ftp.unicode.org/Public//ucd/ with lots of other good info).
For now the info is hard-coded, but I want to take it out and make it easier to update for new Unicode releases
(and add more info about each character, the stuff in UnicodeData.txt, Unihan.zip, Scripts.txt, etc.)
But somehow I don’t really find the time :-)